Bloccare spider inde...
Bloccare spider indesiderati con Robots.txt o .htaccess

Bloccare spider indesiderati con Robots.txt o .htaccess
 Il successo di un sito si misura in gran parte dal numero di utenti che lo visitano, e i motori di ricerca svolgono un importante ruolo in questo. Avere le pagine del sito che si gestisce indicizzate nei motori di ricerca è una delle preoccupazioni primarie dei webmaster, ma come in ogni campo è necessario saper distinguere i motori che porteranno benefici al sito da quelli poco produttivi che alla fine fanno consumare solo banda di traffico e mettono sotto stress i server con le loro ripetute scansioni.
Il successo di un sito si misura in gran parte dal numero di utenti che lo visitano, e i motori di ricerca svolgono un importante ruolo in questo. Avere le pagine del sito che si gestisce indicizzate nei motori di ricerca è una delle preoccupazioni primarie dei webmaster, ma come in ogni campo è necessario saper distinguere i motori che porteranno benefici al sito da quelli poco produttivi che alla fine fanno consumare solo banda di traffico e mettono sotto stress i server con le loro ripetute scansioni.
Siamo tutti d’accordo che essere presenti su Google o Bing sia essenziale, tanto per citare i maggiori, ma accanto a questi esistono diversi motori di ricerca che difficilmente potranno esserci utili, motori che causano solo traffico e carico al server occupando banda e saturando le query ai database MySQL.
Stiamo parlando dei motori di ricerca cinesi, russi, koreani e giapponesi: è comprensibile, a meno che il nostro sito non sia rivolto a questi mercati, con tanto di linguaggio appropriato, che ben difficilmente avremo un beneficio dall’essere indicizzati su di loro.
Non è raro che alcuni nostri clienti si ritrovino all’improvviso ad aver esaurito la banda di traffico mensile a loro disposizione a causa della visita degli spider di questi motori di ricerca, così che si deve ricorrere al più presto ai ripari per cercare di escluderli usando i comandi appropriati da inserire nei file robots.tx o .htaccess
Innanzi tutto, come fare per comprendere quale spider stia scansionando in modo invasivo il nostro sito? Questa è una operazione abbastanza semplice: è necessario consultare i log del server che riportano ogni “chiamata”, cioè registrano ogni operazione che un utente (o uno spider, che non è altro che un utente gestito da un software) esegue sul sito, dalla pagina richiesta alla immagine scaricata e a quanto altro esegue.
Anche la consultazione delle statistiche può essere di aiuto, come ad esempio si può rilevare nella immagine qui sotto dove si nota un notevole consumo (43,21 GB) causato da BOT non meglio identificati (in questo caso sarà necessario consultare i log del server) e subito dopo il consumo del motore di ricerca russo YANDEX:
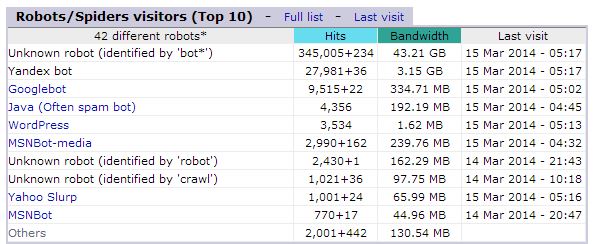
Quando si sono individuati i motori di ricerca da bloccare, si può intervenire sul file robots.txt (soluzione più facile) oppure sul file .htaccess (soluzione un po’ più complessa).
1. Bloccare i crawler usando l’.htaccess
Aprire il file .htaccess, che troviamo nella root del nostro dominio, con un semplice editor di testo (ad esempio il blocco note di Windows, oppure per gli utenti Mac il TextEdit) e inserire i seguenti comandi e salvare:
RewriteCond %{HTTP_USER_AGENT} ^NOME-ROBOT1 [NC,OR”
RewriteCond %{HTTP_USER_AGENT} ^NOME-ROBOTn
RewriteRule ^.*$ - [F”
Esempio:
RewriteEngine on
Options +FollowSymlinks
RewriteBase /
RewriteCond %{HTTP_USER_AGENT} ^Baiduspider [NC,OR”
RewriteCond %{HTTP_USER_AGENT} ^Yandex [NC,OR”
RewriteCond %{HTTP_USER_AGENT} ^Sogou
RewriteRule ^.*$ - [F”
Spiegazione:
- Gli User-Agents da bloccare vengono listati riga per riga (sostituire NOME-ROBOTn con il nome effettivo del robots da bloccare)
- Le varie condizioni (righe) sono connesse fra loro tramite l’operatore booleano “OR”
- “NC” = “no case” -> Significa che l’esecuzione sarà nella modalità case-insensitive (quindi insensibile alle maiuscole/minuscole)
- Il carattere “^” indica che il nome dell’User Agent deve iniziare con quella stringa di testo (quindi vengono filtrati tutti gli accessi che iniziano col nome dell’agente)
- “[F”” = offre allo spider l’istruzione “Forbidden” (accesso proibito)
2. Bloccare gli user-agents usando il file robots.txt
Il file robots.txt è specifico per fornire istruzioni ai bots che scansionano i siti, è uno standard uniformemente adottato che ogni spider legge ed esegue le istruzioni in esso contenute prima di navigare il sito.
Anche in questo caso apriamo col nostro editor di testo il file robots.txt che troviamo nella ROOT del nostro sito (se il file non esiste, possiamo crearlo nuovo):
Sintassi:
User-agent: NOME-ROBOT1 User-agent: NOME-ROBOT2 User-agent: NOME-ROBOTn Disallow: DIRECTORY _DA_BLOCCARE
Esempio:
User-agent: Googlebot-Image User-agent: Yandex User-agent: Slurp/2.0 Disallow: /
Spiegazione:
- User-agent: = indica il nome dell’agente al quale ci rivolgiamo
- Disallow: = significa NON accedere/indicizzare
- / = la root del sito (quindi l’intera directory del sito, avremmo potuto anche bloccare l’accesso solo alla directory di amministrazione “/admin” oppure solo quela relativa alle immagini “/images”)
- In questo esempio blocchiamo l’accesso agli spider di Google Images, Yandex (motore di ricerca Russo) e Inktomi (Hotbot-Lycos-NBCi)
Questa soluzione è pratica e veloce, tuttavia non sicura al 100%, ma comunque sufficientemente efficace.
Un buon file robots.txt per siti con pubblico esclusivamente italiano potrebbe essere questo:
# MOTORI DI RICERCA GIAPPONESI User-agent: moget User-agent: ichiro Disallow: / # MOTORI DI RICERCA KOREANI User-agent: NaverBot User-agent: Yeti Disallow: / # MOTORI DI RICERCA CINESI User-agent: Baiduspider User-agent: Baiduspider-video User-agent: Baiduspider-image User-agent: sogou spider User-agent: YoudaoBot Disallow: / # MOTORI DI RICERCA RUSSI User-agent: Yandex Disallow: /
Attenzione: gli spider sono molto sensibili al file robots.txt, Googlebot in particolare, per questo motivo si deve prestare estrema attenzione nell’usare questa funzione inserendo solo istruzioni di cui si sia certi che non causino danni, nel breve-medio e lungo termine.